

AMD Instinct MI300A

CDNA3 Architecture
HPC、AI、Data Science
- 128GB HBM3 Memory
- CPU up to 24 cores
- TDP 550W
AMD Instinct MI300A は、AI や HPCでの処理を強化するよう設計されており x86プロセッサと AMD Instinct アクセラレータ、HBM3 メモリを 1つのパッケージに統合した APU(アクセラレーテッド プロセッシング ユニット)です。CPU と GPU がメモリアドレス空間を共有し内部インターコネクトの帯域を圧迫せず高性能化を実現しており、電力効率の高いチップレットテクノロジによる高度なパッケージングが特徴です。
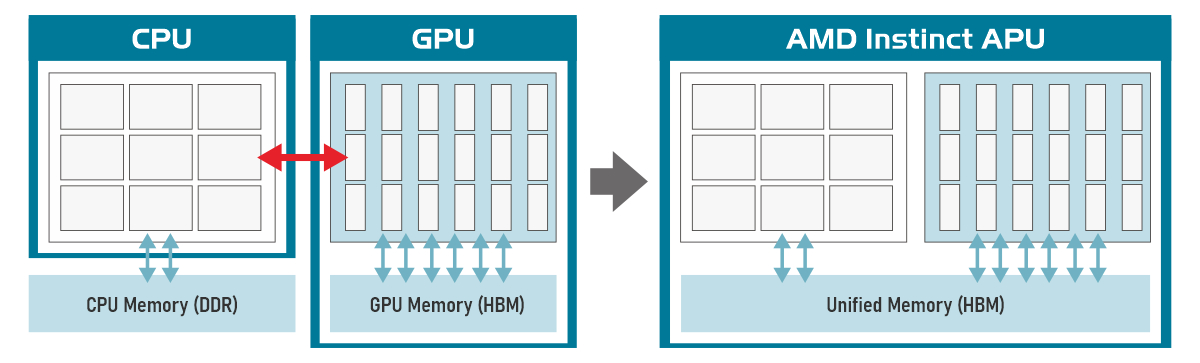
CPU仕様
| AMD EPYC CPU Architecture | Zen 4 |
| CPU コア | 24 |
| CPU ピーク エンジン クロック | 3700 MHz |
GPU仕様
| GPU アーキテクチャ | CDNA3 |
| Lithography | TSMC 5nm | 6nm FinFET |
| ストリーミング プロセッサ | 14,592 |
| マトリックス コア | 912 |
| 演算ユニット | 228 |
| ピーク時エンジン クロック | 2100 MHz |
| 8 ビット精度 (FP8) ピーク性能 (E5M2、E4M3) |
1.96 PFLOPs |
| 構造スパース性を持つ 8 ビット精度 (FP8) ピーク性能 (E5M2、E4M3) |
3.92 PFLOPs |
| 半精度 (FP16) ピーク性能 | 980.6 TFLOPs |
| 構造スパース性を持つ半精度 (FP16) ピーク性能 |
1.96 PFLOPs |
| 単精度 (TF32 マトリックス) ピーク性能 |
490.3 TFLOPs |
| 構造スパース性を持つ単精度 (TF32) ピーク性能 |
980.6 TFLOPs |
| 単精度マトリックス (FP32) ピーク性能 |
122.6 TFLOPs |
| 倍精度マトリックス (FP64) ピーク性能 |
122.6 TFLOPs |
| 単精度 (FP32) ピーク性能 | 122.6 TFLOPs |
| 倍精度 (FP64) ピーク性能 | 61.3 TFLOPs |
| INT8 のピーク性能 | 1.96 POPs |
| 構造スパース性を持つ INT8 ピーク性能 |
3.92 POPs |
| bfloat16 ピーク性能 | 980.6 TFLOPs |
| 構造スパース性を持つ bfloat16 ピーク性能 |
1.96 PFLOPs |
| トランジスタ数 | 146 Billion |
Memory仕様
| ラスト レベル キャッシュ (LLC) | 256 MB |
| 専用メモリ サイズ | 128 GB |
| 専用メモリ タイプ | HBM3 |
| Infinity Cache | Yes |
| メモリ インターフェイス | 8192ビット |
| メモリ クロック | 5.2 GHz |
| ピーク メモリ帯域幅 | 5.3 TB/s |
| メモリ ECC サポート | 〇 (フルチップ) |
その他仕様
| GPU フォーム ファクター | APU SH5 ソケット |
| バス タイプ | PCIe 5.0 x16 |
| Infinity Fabric Links | 8 |
| Infinity Fabric リンク ピーク帯域幅 |
128 GB/s |
| TDP | 550W | 760W Peak |
AMD CDNA 3 アーキテクチャ
AMD CDNA 3 は、AMD Instinct MI300 シリーズ アクセラレータの基盤となる演算専用アーキテクチャです。データ移動のオーバーヘッドを削減し電力効率を高めるよう設計されたチップレットテクノロジによる高度なパッケージングが特徴です。

White Paper

AMD ROCm ソフトウェア
AMD CDNA アーキテクチャは AMD Instinct アクセラレータをターゲットとする AI および HPC ソリューション開発のためのプログラミングモデルやツール、コンパイラやライブラリ、ランタイムの幅広いセットを含むオープンソフトウェアスタックである AMD ROCm によってサポートされています。
最適化された GPU ソフトウェアスタック
AMD ROCm は、オープンソフトウェアスタックです。低レベルのカーネルからエンドユーザーアプリケーションに至るまで、GPU プログラミングを可能するドライバーや開発ツール、API が揃っています。ROCm は生成 AI および HPC アプリケーションに対して最適化されており既存のコードも簡単に ROCm に移行できます。

ROCm 6 の新機能
- AMD Instinct MI300A および MI300X アクセラレータに対するサポートを拡大
- 主な AI 対応機能: ROCm 変換エンジン、高度に最適化された Attention アルゴリズム、実証済みの集団通信ライブラリ
- 最適化されたパフォーマンス: 動的な FP16、BF16、FP8 の使用、最適化された HIPGraph
- 開発者の成功を実現: 構造スパース性と量子化ライブラリのサポート
- 最新のフレームワーク、モデル、ML パイプラインによりエコシステムの拡大をサポート
Resource notes
https://rocm.docs.amd.com/en/latest/about/release-notes.html
AI のための AMD ROCm ソフトウェア
開発者が AI アプリケーションを AMD GPU 上で最適化可能に
Document

AMD ROCm Developer Hub
https://www.amd.com/en/developer/resources/infinity-hub.html
AMD Instinct MI300A vs NVIDIA H100
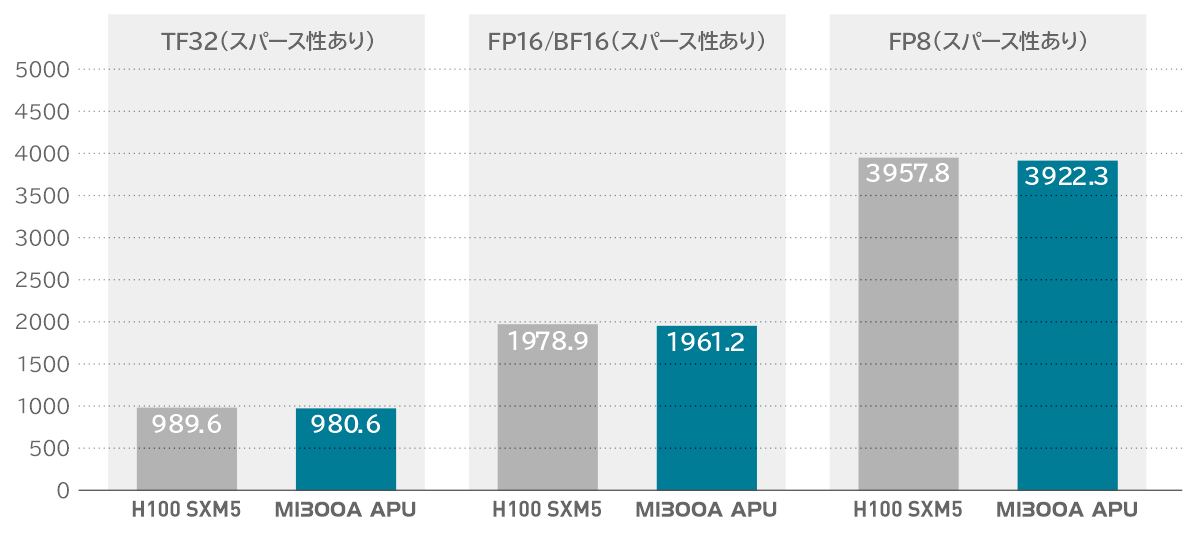
AI パフォーマンス (ピーク TFLOPs)
競合アクセラレータと比較して最大 1.3 倍の AI パフォーマンス
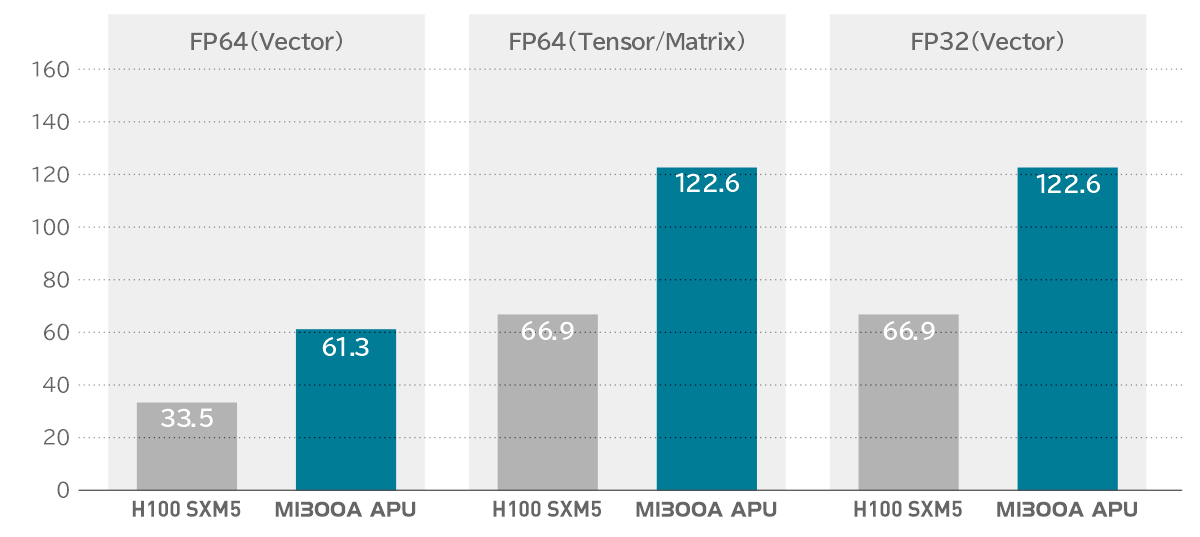
HPC 性能 (ピーク TFLOPs)
競合アクセラレータと比較して最大 2.4 倍の HPC 性能
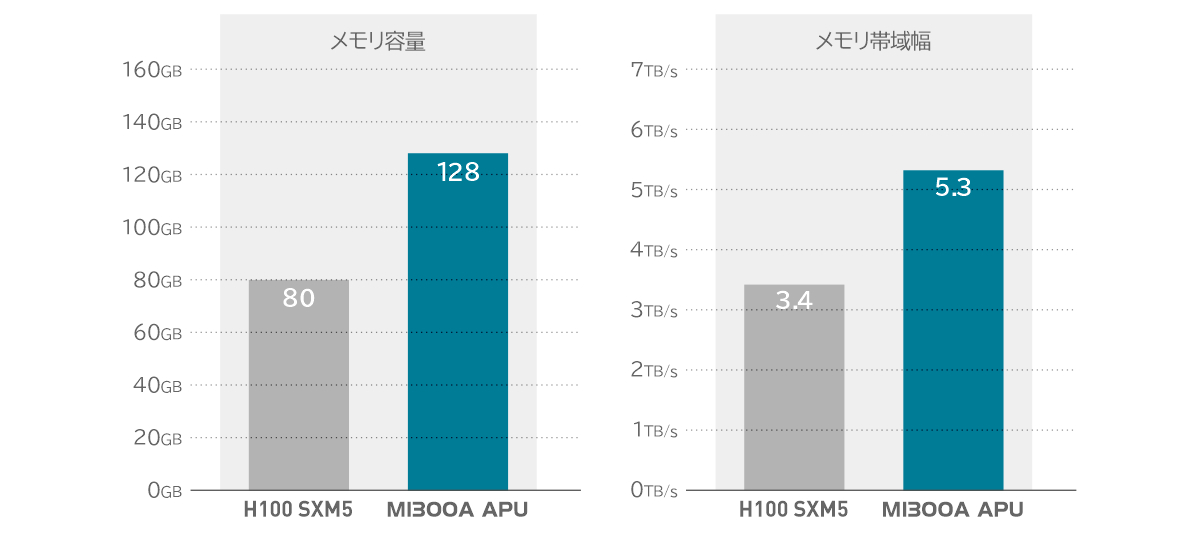
メモリの容量と帯域幅
競合アクセラレータと比較して 2.4 倍のメモリ容量と 1.6 倍のピーク理論メモリ帯域幅
AMD Instinct MI300A, MI300X 搭載サーバカタログ

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。