

NVIDIA Grace CPU & NVIDIA Grace Hopper

NVIDIA Grace CPU and Arm Architecture
最大級の AI、HPC、クラウド、ハイパースケール ワークロードを高速化
AI モデルは、数十テラバイト規模のデータを活用したより精度の高いレコメンダー システム、数千億のパラメーターを持つ対話型 AI 、科学的なさらなる発見などによって、複雑さとサイズが爆発的に増加増大しています。これらの巨大モデルをスケーリングするには、大量のメモリ プールに高速アクセスし、CPU と GPU が密結合した新しいアーキテクチャが必要です。NVIDIA Grace™ CPU は、高性能、優れた電力効率性、高帯域幅の接続性を実現し、データ センターのさまざまなニーズに合わせて多様な構成で使用することができます。
NVIDIA Grace CPU Superchip
NVIDIA Grace CPU Superchipは、NVLink-C2C技術を採用し、144個の Arm® Neoverse V2コアと 1テラバイト/秒(TB/s)のメモリ帯域幅を提供します。

特徴
- Up to 144 high-performance Arm Neoverse V2 Cores with 4x128b SVE2
- High-performance NVIDIA Scalable Coherency Fabric with 3.2 terabytes per second (TB/s) bisection bandwidth
- Up to 960 gigabytes (GB) of LPDDR5X memory with error-correction code (ECC) with up to 1TB/s of memory bandwidth
- 900GB/s NVLink-C2C
- 500W module (CPU + memory)
2X More Data Center Throughput in Cloud and HPC Apps

Data center-level projection of NVIDIA Grace Superchip vs. x86 flagship dual-socket data center systems (112 and 192 core systems). CFD: OpenFOAM (Motorbike| Small) Big Data: HiBench+Kmeans Spark (HiBench 7.1.1, Hadoop 3.3.3, Spark 3.3.0) and Microservices: Google Protobufs (Commit 7cd0b6fbf1643943560d8a9fe553fd206190b27f | N instances in parallel).
Preliminary Product Specifications
| Feature | ||
|---|---|---|
| Core count | 144 Arm Neoverse V2 Cores with 4x128b SVE2 | |
| L1 cache | 64KB i-cache + 64KB d-cache | |
| L2 cache | 1MB per core | |
| L3 cache | 234MB | |
| LPDDR5X size | 240GB, 480GB and 960GB<br> on-module memory options |
|
| Memory bandwidth | Up to 1TB/s | |
| NVIDIA NVLink-C2C bandwidth | 900GB/s | |
| PCIe links | Up to 8x PCIe Gen5 x16 option to bifurcate | |
| Module thermal design power(TDP) | 500W TDP with memory | |
| Form factor | Superchip module | |
| Thermal solution | Air cooled or liquid cooled | |
NVIDIA Grace Hopper Superchip
NVIDIA Grace Hopper™ Superchip は、NVIDIA® NVLink®-C2C を使用して Grace および Hopper 両方のアーキテクチャを組み合わせ、高速化された AI およびハイ パフォーマンス コンピューティング (HPC) アプリケーション向けの CPU + GPU コヒーレント メモリ モデルを提供します。

特徴
- 72-core NVIDIA Grace CPU
- NVIDIA H100 Tensor Core GPU
- Up to 480GB of LPDDR5X memory with error-correction code (ECC)
- Supports 96GB of HBM3 or 144GB of HBM3e
- Up to 624GB of fast-access memory
- NVLink-C2C: 900GB/s of coherent memory
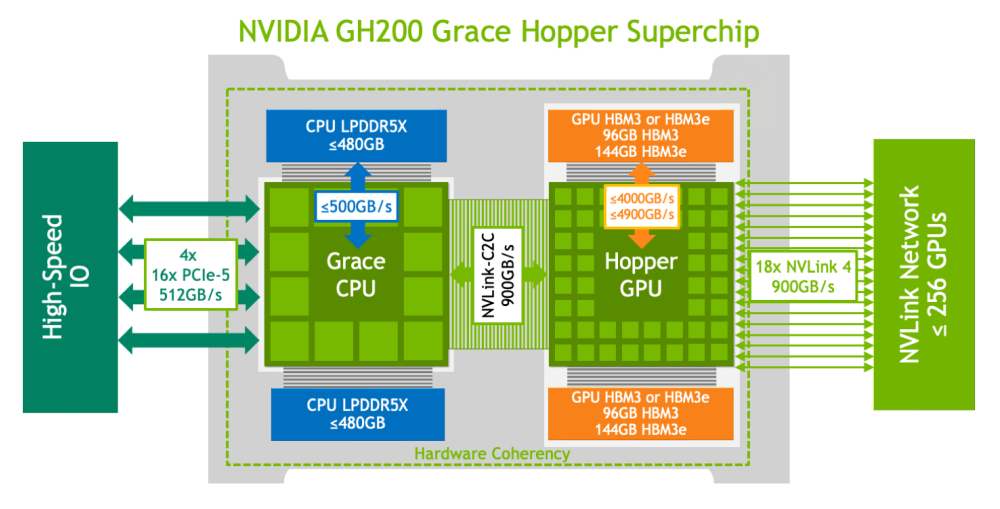
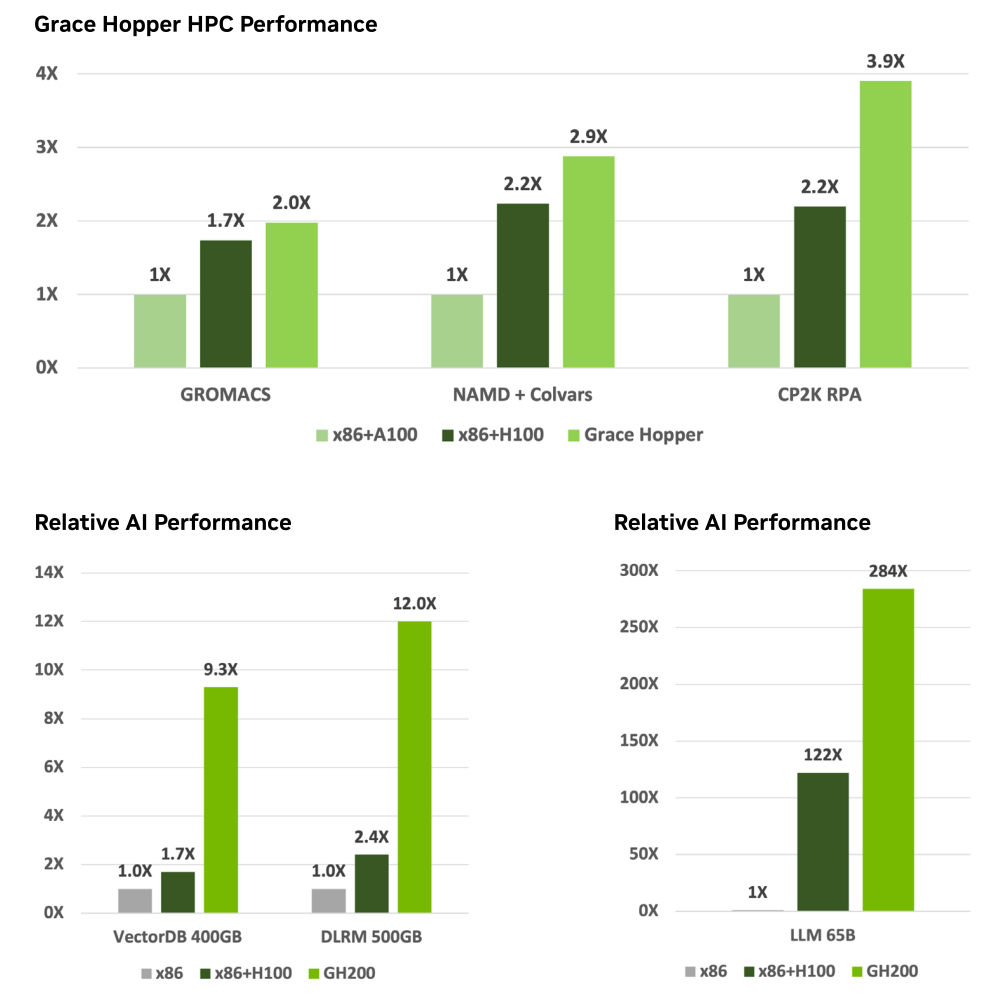
Product Specifications
| Grace CPU | Feature | |
|---|---|---|
| Core count | 72 Arm Neoverse V2 cores | |
| L1 cache | 64KB i-cache + 64KB d-cache | |
| L2 cache | 1MB per core | |
| L3 cache | 117MB | |
| LPDDR5X size | Up to 480GB | |
| Memory bandwidth | Up to 512GB/s | |
| PCIe links | Up to 4x PCIe x16 (Gen5) | |
| Hopper H100 GPU | Feature | |
|---|---|---|
| FP64 | 34 teraFLOPS | |
| FP64Tensor Core | 67 teraFLOPS | |
| FP32 | 67 teraFLOPS | |
| TF32 Tensor Core | 989 teraFLOPS* | 494 teraFLOPS | |
| BFLOAT16 Tensor Core | 1,979 teraFLOPS* | 990 teraFLOPS | |
| FP16 Tensor Core | 1,979 teraFLOPS* | 990 teraFLOPS | |
| FP8 Tensor Core | 3,958 teraFLOPS* | 1,979 teraFLOPS | |
| INT8 Tensor Core | 3,958 TOPS* | 1,979 TOPS | |
| High-bandwidth memory (HBM) size | Up to 96GB | 144GB HBM3e | |
| Memory bandwidth | Up to 4TB/s | Up to 4.9TB/s HBM3e | |
| NVIDIA NVLink-C2C CPU-to-GPU bandwidth | 900 GB/s bidirectional | |
| Module thermal design power (TDP) | Programmable from 450W to 1000W (CPU + GPU + memory) | |
| Form factor | Superchip module | |
| Thermal solution | Air cooled or liquid cooled | |
With sparsity
Take a Look at the Grace Lineup of Superchips
NVLink-C2C で CPU と GPU の接続を高速化します
AI と HPC に関する最大級の問題を解決するには、大容量メモリと高帯域幅メモリ (HBM) が必要です。第 4 世代の NVIDIA NVLink-C2C では、NVIDIA Grace CPU と NVIDIA GPU 間の双方向帯域幅が 1 秒あたり 900 ギガバイト (900GB/秒) にもおよびます。この接続により、システムと HBM GPU メモリを組み合わせて、シンプルなプログラム性を実現する、統合されたキャッシュコヒーレント メモリ アドレス空間が提供されます。CPU と GPU 間のこのコヒーレントな高帯域幅接続は、将来直面する非常に複雑な問題を解決するための鍵となります。
LPDDR5X で高帯域幅メモリを活用
NVIDIA Grace は、データ センターの要件を満たすために、エラー修正コード (ECC) などのメカニズムによってサーバー クラスの信頼性を持った LPDDR5X メモリを活用した初のサーバー CPU です。また、現行のサーバー メモリに比べて 2 倍のメモリ帯域幅と、最大 10 倍の電力効率を実現します。NVIDIA Grace LPDDR5X ソリューションは、大規模で高性能な最高レベルのキャッシュと相まって、大規模モデルに必要な帯域幅を提供すると同時に、システム電力を削減して次世代のワークロードのパフォーマンスを最大限に引き出します。
Arm Neoverse V2 コアで性能と効率性を向上
GPU の並列計算性能は進歩し続けており、CPU で実行されるシリアル タスクによってワークロードはコントロールすることができます。高速で効率的な CPU は、ワークロードを最大限に高速化するために、システム設計にとって重要な要素です。NVIDIA Grace CPU は、NVIDIA が設計した Scalable Coherency Fabric と Arm Neoverse V2 コアを統合し、電力効率に優れた設計で高い性能を引き出し、科学者や研究者のライフワークを大いに助けます。
HBM3 および HBM3e GPUメモリで生成 AI をスーパーチャージ
生成 AI はメモリと計算リソースを大量に使います。NVIDIA GH200 Grace Hopper Superchip は、96GB の HBM3 メモリを使用し、オリジナルの A100 の 2.5 倍以上の GPU メモリ帯域幅を提供します。次世代の GH200 は 141GB の HBM3e メモリ テクノロジを活用する世界初のプロセッサであり、オリジナルの A100 の 3 倍以上の帯域幅を提供します。NVIDIA Grace Hopper の HBM が NVLink-C2C 経由で CPU メモリと連携することで、600 GB を超える高速アクセス メモリを GPU に提供し、アクセラレーテッド コンピューティングや生成 AI の非常に複雑なワークロードを処理するために必要なメモリ容量と帯域幅を提供します。

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。