

NVIDIA RTX 5000 Ada

NVIDIA RTX™ 5000 Ada 世代 GPU は、100基の第 3世代 RTコアと 400基の第 4世代 Tensorコア、さらに 12,800基の CUDAコアと 32GBのグラフィックスメモリを搭載したプロフェッショナル用グラフィックスボードです。前世代と比較して最大 2倍のパフォーマンスを実現し、レイトレーシングや物理演算シミュレーション、ニューラルグラフィックスや生成 AIなど、現代の産業における要求の厳しいワークロードに対処できるように設計されています。

NVIDIA Ada Lovelace アーキテクチャ搭載

Ada Lovelace アーキテクチャベース CUDAコア
単精度浮動小数点 (FP32) 演算を前世代の 2 倍に高速化したことで、デスクトップにおける複雑な 3D のコンピューター支援設計 (CAD) とコンピューター支援エンジニアリング (CAE) などのグラフィックスやシミュレーションのワークロードのパフォーマンスを大幅に向上しました。
第 3世代 RTコア
前世代と比較して 2 倍以上のスループットを提供する第 3 世代 RT コアにより、動画コンテンツのフォトリアルなレンダリング、アーキテクチャ デザインの評価、製品デザインの仮想プロトタイプといったワークロードで大幅な高速化を実現します。このテクノロジにより、レイトレーシング使用のモーション ブラー レンダリングも高速化するため、ビジュアル精度が向上します。

第 4世代 Tensorコア
第 4世代の Tensorコアは前世代の 4倍以上の AIコンピューティングパフォーマンスを提供します。これらの Tensorコアは、FP8精度データ型の高速化をサポートし、独立した浮動小数点と整数のデータパスを提供し、浮動小数点と整数の混合計算の実行を高速化します。
32GB GPUメモリ
32GB GDDR6メモリを搭載した RTX 5000 ADAは、データ サイエンティスト、エンジニア、クリエイティブなどの分野のプロフェッショナルたちのために、レンダリング、データ サイエンス、シミュレーションなどの膨大なデータセットやワークロードを使用する作業に必要な大容量メモリを提供します。
AV1 エンコーダー
AV1エンコーディングと共に第 8世代の専用ハードウェアエンコーダー (NVENC)を備えたことで、ストリーマー、配信者、ビデオ会議の新しい可能性を解き放ちます。H.264 よりも 40%効率的で、1080pでストリーミングしているユーザーは、同じビットレートと品質で実行しながら、ストリーミングの解像度を 1440pまで上げることができます。

仮想化対応
NVIDIA RTX仮想ワークステーション (vWS)ソフトウェアをサポートすることで、個人向けワークステーションを複数のハイパフォーマンスな仮想ワークステーション インスタンスとして使用できるため、離れた場所にいるユーザー同士がリソースを共有し、ハイエンドのデザイン、AI、コンピューティングのワークロードを実行することができます。
パフォーマンス
グラフィックス
3840×2160 resolution, SPECviewperf 2020 Siemens NX viewset tests.
レンダリング
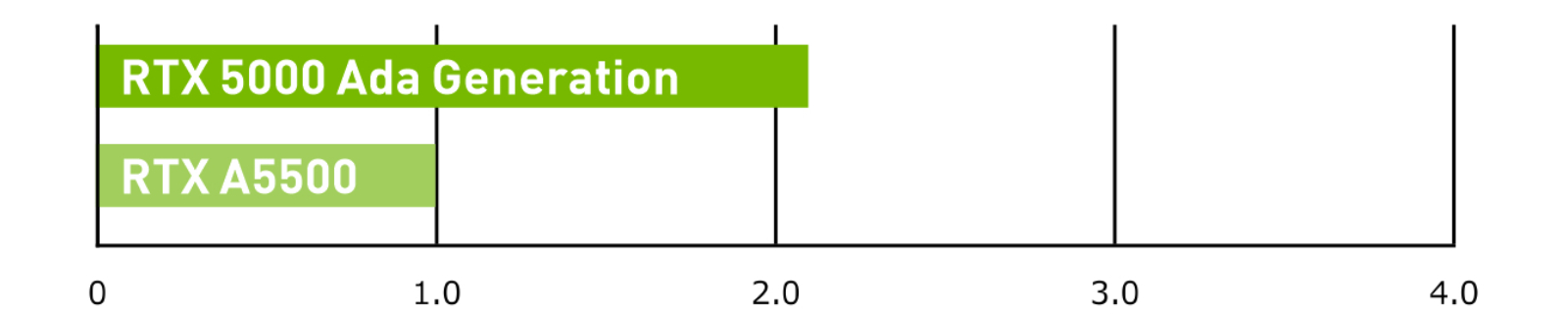
1920×1080 resolution, Chaos V-Ray v5.0.
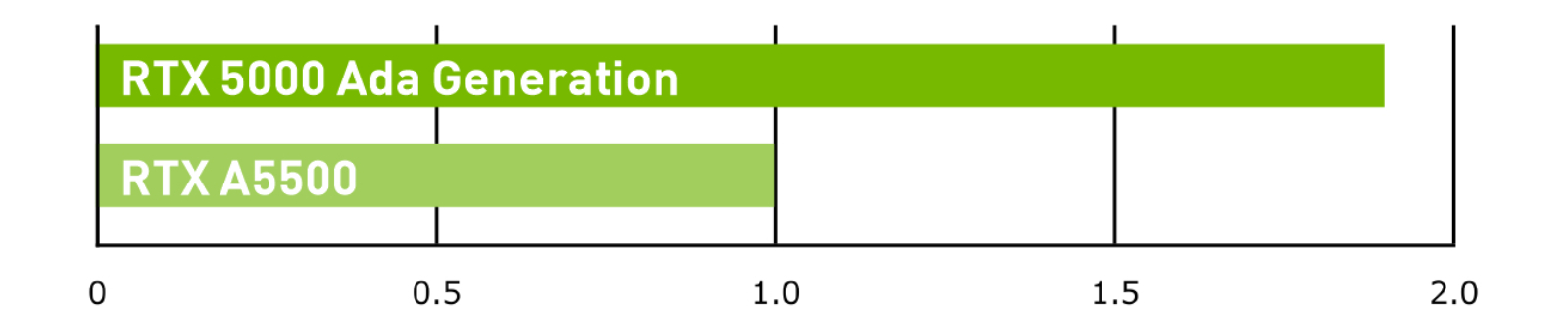
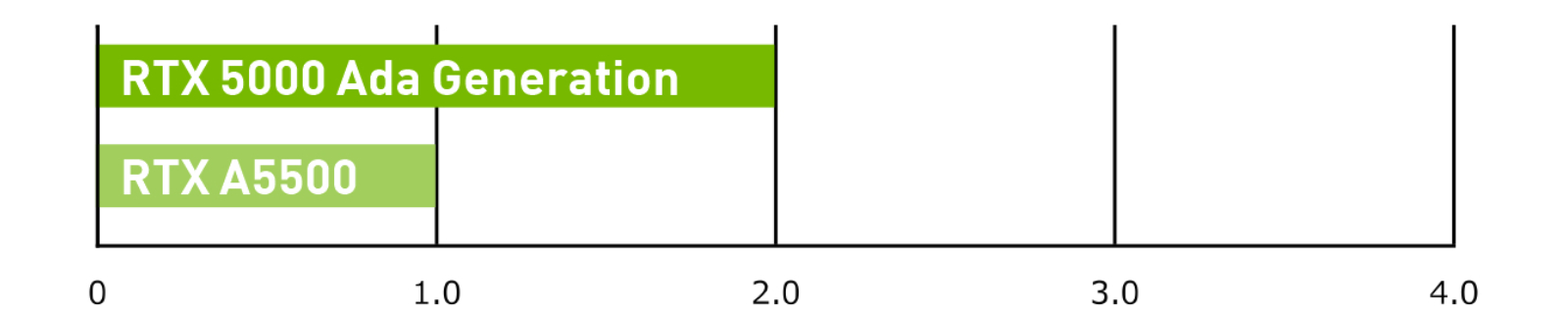
生成 AI
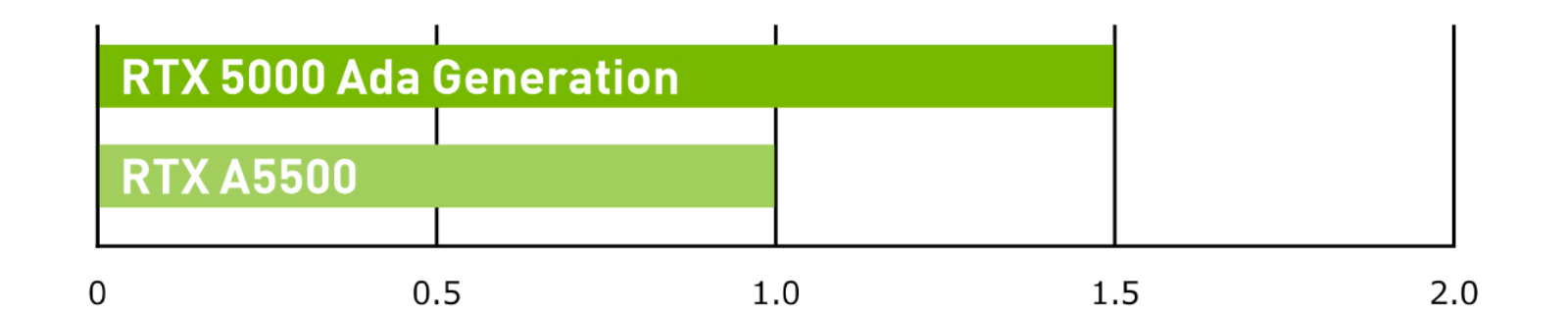
RTX 5000 Ada Generation vs RTX A5500 image generation, 512×512 Stable Diffusion webUI v1.3.1.
ハイパフォーマンス コンピューティング
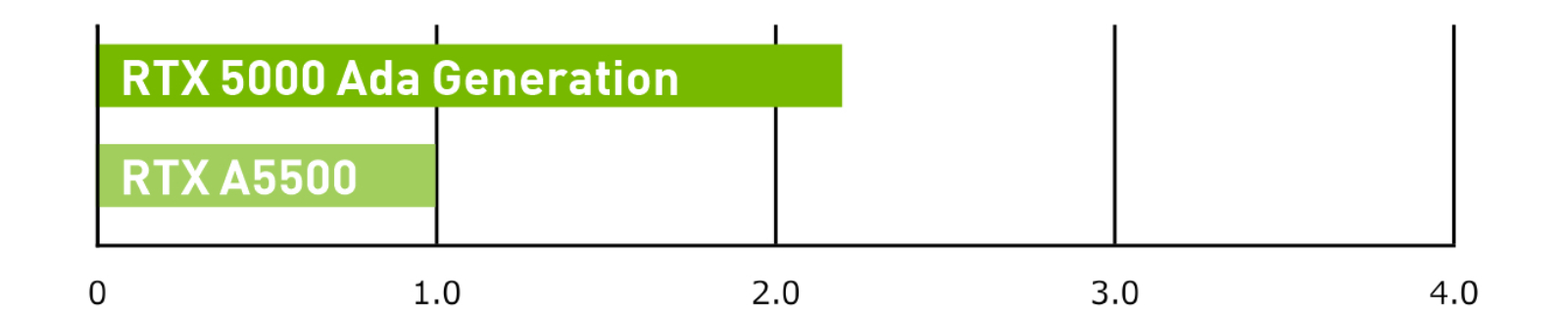
CUDA Toolkit 11.8 (cuBLAS performance), precision = INT8, input = zero.
Omniverse
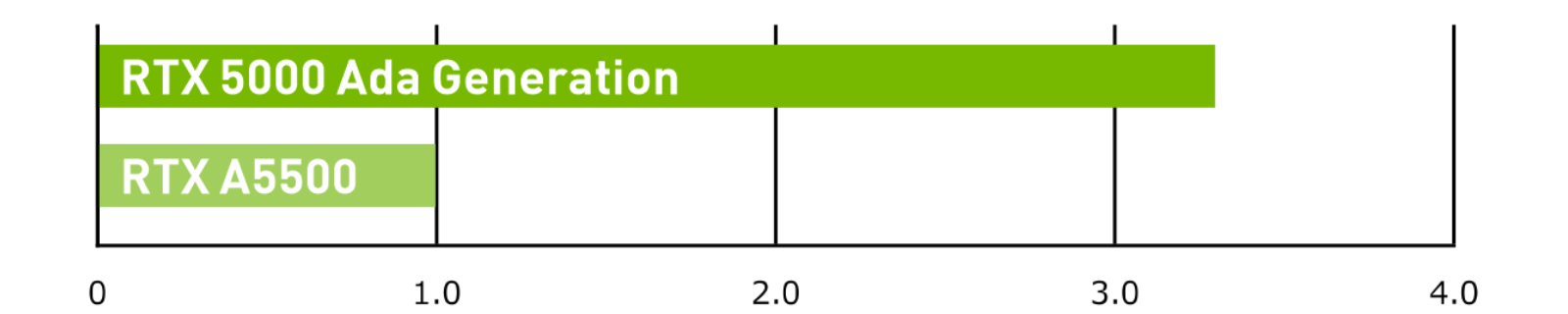
NVIDIA Omniverse performance for real-time rendering at 4K with NVIDIA Deep Learning Super Sampling (DLSS) 3.
AI 推論
TensorRT, ResNet-50 V1.5 Inference, precision: mixed.
NVIDIA RTX 5000 Ada データシート

RTX 5000 Ada / RTX 6000 Ada 仕様比較
| RTX 5000 Ada | RTX 6000 Ada | |
| Architecture | Ada Lovelace | Ada Lovelace |
| CUDA Cores | 12,800 | 18,176 |
| Gen4 Tensor Cores | 400 | 568 |
| Gen3 RT Cores | 100 | 142 |
| Single-Precision Performance | 65.3 TFLOPS* |
91.1 TFLOPS* |
| Tensor Performance | 1044.4 TFLOPS** | 1457.0 TFLOPS** |
| FP8 | 対応 | 対応 |
| VRAM | 32GB GDDR6 | 48GB GDDR6 |
| Memory Band Width | 576GB/s | 768 GB/s |
| Memory Interface | 256 bit | 384 bit |
| NVLink | No | No |
| Graphics Bus | PCIe Gen4 x 16 | PCIe Gen4 x 16 |
| Output | DP x4 | DP x4 |
| TDP | 250W | 300W |
* GPU ブースト クロックに基づくピーク レート。
** スパース性を使用した実効 FP8 テラ FLOPS (TFLOPS)。
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。