

XILINX ALVEO Series

FPGA Accelerator Card
XILINX ALVEO シリーズは FPGA を搭載し、機械学習やデータ分析、ビデオ処理などの演算負荷の高いワークロードを加速するために設計されたアクセラレータカードです。簡単に扱えるようアプリケーションやライブラリが準備されており、ソフトウェア開発者向けには Vitis 統合ソフトウェアプラットフォーム(無償)を使うことができます。アプリケーションの開発やプロファイリングなどを行え、C/C++ および OpenCL などの言語をサポートします。
動的ワークロードを高速化
高速 – 最高性能
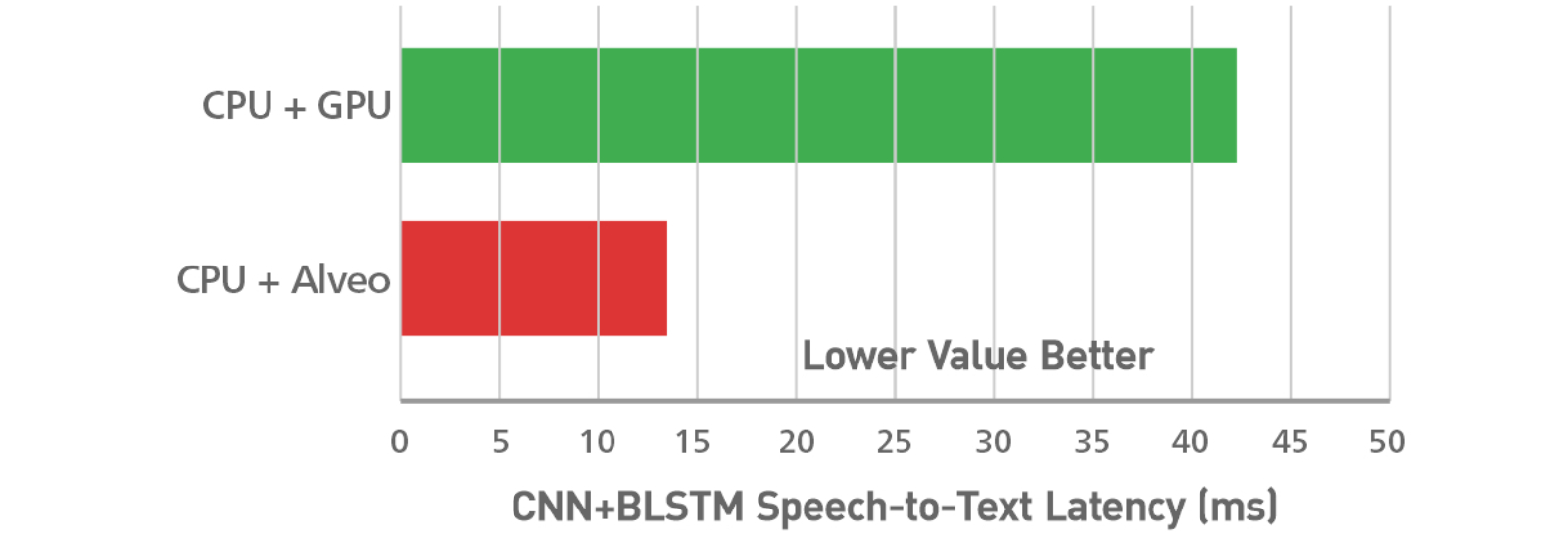
- GPU ベースのソリューションと比べて、推論のスループットは 4倍以上、レイテンシは3倍向上※。
(※ NVIDIA P4 に対して CNN+BLSTM の Speech-to-Text ML推論で計測)
適応性 – 高レベルのデザインを加速
- 同じアクセラレータカードで、機械学習の推論からビデオ処理まであらゆるワークロードに対応。
- リコンフィギャラブルハードウェアでワークロードアルゴリズムの進化にも素早く適応。
アクセシブル – Cloud ←→ On-Premises Mobility
- クラウドとオンプレミスでソリューションを相互運用でき、アプリケーション要件に対応する拡張性に優れる。
- 一般的なワークロードに対応するアプリケーション、または アプリケーション開発者ツールを利用して独自のアプリケーションを構築。
XILINX ALVEO シリーズ
| Alveo U200 | Alveo U250 | Alveo U280 | Alveo U50 |
 |
 |
 |
 |
| Product | Alveo U200 | Alveo U250 | Alveo U280 | Alveo U50 | |
| Dimensions | Width | Dual Slot | Dual Slot | Dual Slot | Single Slot |
| Form Factor Passive |
Full Height, ¾ Length |
Full Height, ¾ Length |
Full Height, ¾ Length |
Half Height, ½ Length |
|
| Form Factor Active |
Full Height, Full Length |
Full Height, Full Length |
Full Height, Full Length |
– | |
| Logic Resources |
Look Up Tables |
1,182K | 1,728K | 1,304K | 872K |
| Registers | 2,364K | 3,456K | 2,607K | 1,743K | |
| DSP Slices | 6,840 | 12,288 | 9,024 | 5,952 | |
| DRAM Memory |
DDR Format | 4x 16GB 72b DIMM DDR4 |
4x 16GB 72b DIMM DDR4 |
4x 16GB 72b DIMM DDR4 |
– |
| DDR Total Capacity |
64GB | 64GB | 32GB | – | |
| DDR Max Data Rate |
2400MT/s | 2400MT/s | 2400MT/s | – | |
| DDR Total Bandwidth |
77GB/s | 77GB/s | 38GB/s | – | |
| HBM2 Total Capacity |
– | – | 8GB | 8GB | |
| HBM2 Total Bandwidth | – | – | 460GB/s | 460GB/s | |
| Internal SRAM |
Total Capacity |
43MB | 57MB | 43MB | 28MB |
| Total Bandwidth |
37TB/s | 47TB/s | 35TB/s | 24TB/s | |
| Interface | PCI Express | Gen3 x16 | Gen3 x16 | Gen3 x16, 2xGen4 x8, CCIX |
Gen3 x16, 2xGen4 x8, CCIX |
| Network Interface |
2x QSFP28 | 2x QSFP28 | 2x QSFP28 | U50 – 1x QSFP28 U50DD – 2x SFP DD |
|
| Power and Thermal |
Thermal Cooling |
Passive, Active | Passive, Active | Passive, Active | Passive |
| Typical Power |
100W | 110W | 100W | 50W | |
| Maximum Power |
225W | 225W | 225W | 75W | |
| Time Stamp | Clock Precision |
– | – | – | IEEE Std 1588 |
| Time Stamp | Vitis Developer Environment |
Yes | Yes | Yes | Yes |
すぐに使えるアプリケーションおよびライブラリ
サポートするワークロード
- Data Analytics
- Tools and Services
- Machine Learning
- Video and Image Processing
- Networking and Security
- Financial Computing
- High Performance Computing
- Storage and Compression
- Genomics
Accelerated Application Container Catalog
Vitis 統合ソフトウェア プラットフォーム

Vitisは、すべての開発者が XILINX社の FPGA、SoC、および Versal ACAPを活用し、AIや深層学習など、エッジやクラウドにかかわらず高い演算性能要件を満たすアプリケーションを構築できるようサポートします。
Vitis 統合ソフトウェア プラットフォームの内容
- アクセラレーション アプリケーションをシームレスに構築するための包括的なコア開発キット。
- ザイリンクスの FPGA および Versal ACAP ハードウェア プラットフォーム向けに最適化された、ハードウェア アクセラレーション用の豊富なオープンソース ライブラリ。
- 使い慣れた高レベルのフレームワークを利用して直接開発できる、プラグイン タイプのドメイン特化開発環境。
- パートナー提供のライブラリおよび構築済みアプリケーションが利用できるエコシステム。
Vitis 統合ソフトウェア開発プラットフォームの重要なコンポーネント
Vitis AI 開発環境
- Vitis AI 開発環境は、ザイリンクスのエンベデッド プラットフォーム、Alveo アクセラレータカード、またはクラウド内の FPGA インスタンスで AI 推論を高速化するための開発環境。
- Vitis AI 開発環境は、Tensorflow や Caffee など最先端の深層学習フレームワークをサポートし、包括的な API を提供。
- この Vitis AI は、トレーニング済みのネットワークをプルーニング、量子化、最適化、およびコンパイルし、運用するアプリケーションの AI 推論性能を最大化。
Vitis アクセラレーション ライブラリ
- C、C++、または Python で記述された既存アプリケーションに最小限のコード変更を加えるだけで高速化を可能にする、アクセラレーションに最適化されたオープンソース ライブラリです。
- ドメイン別のアクセラレーション ライブラリをそのまま利用することも、要件に合わせて変更することも、さらには独自のアクセラレータでアルゴリズム構築ブロックとして使用することもできます。
Vitis コア開発キット
- Vitis コンパイラ、アナライザー、デバッガーなどを含み、GUI およびコマンドラインで利用可能な包括的な開発ツールです。
- C、C++、または OpenCL で開発されたアクセラレーション アルゴリズムの構築、性能ボトルネックの分析、デバッグが可能です。
- これらの機能は自身の IDE 内でだけでなく、Vitis IDE スタンドアロンでも利用できます。
ザイリンクス ランタイム ライブラリ
- ザイリンクス ランタイム (XRT) は、アプリケーション コード (エンベデッド Arm または x86ホストで実行) と、PCIe ベースのザイリンクス アクセラレータ カード、MPSoC ベースのエンベデッド プラットフォーム、または ACAP の再構成可能な部分に含まれたアクセラレータとの通信を容易にします。
- ユーザー スペース ライブラリと API、カーネル ドライバー、ボード ユーティリティ、ファームウェアが含まれます。
Vitis ターゲット プラットフォーム
- オンプレミスまたはクラウドでのザイリンクス アクセラレータ カードの場合、Vitis ターゲットプラットフォームは FPGA アクセラレータと x86 アプリケーション コード間を接続して通信を管理する PCIe インターフェイスを自動構成します。設計者が細かい接続を構成する必要はありません。
- ザイリンクスのエンベデッド デバイスの場合、Vitis ターゲット プラットフォームには、プラットフォーム上のプロセッサ用オペレーティング システム、プラットフォーム ペリフェラル用ブートローダーとドライバー、およびルート ファイル システムも含まれます。
- ザイリンクスの評価ボード用にあらかじめ定義された Vitis ターゲット プラットフォームを使用できますが、Vivado Design Suite で独自に定義することも可能です。

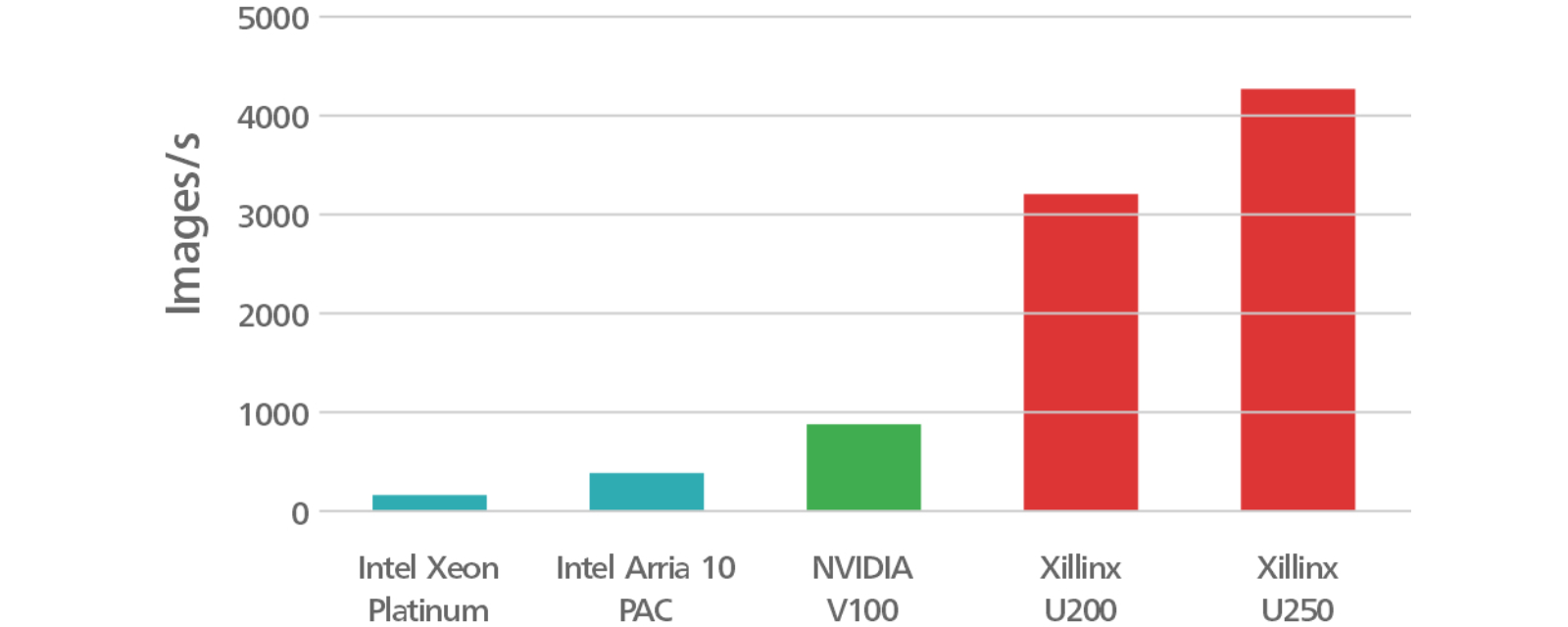
Benchmark Data
Alveo U200 ・ Alveo U250
リアルタイム機械学習※の処理能力は 20 倍向上 機械学習推論のレイテンシは 1/3 に低減

※GoogLeNet V1:ホワイトペーパー『ザイリンクス Alveo アクセラレータカードを使用した DNN の高速化』
CPU + GPU:NVIDIA P4 + Intel Xeon E5-2690v4 @2.60GHz(56 Core)
CPU + Alveo:Alveo U200 または U250 + Intel Xeon E5-2686v4 @2.3GHz(8 Core)
Alveo U50
金融シミュレーション – グリッドコンピューティング
- 最短でインサイトを獲得
- 運用コストを削減し、電力効率を最大化
- 確定的なレイテンシによる安定した性能
モンテカルロシミュレーション
性能と効率性(パス/秒/W)
超低レイテンシネットワーク
- 低レイテンシ(20 分の 1)
- Alveo U50 は、レイテンシが 10uの CPUと比較して、500us 以下の取引時間を実現
- 確定的なスループットタイミング章
取引時間の高速化
マーケットデータから TCP メッセージ(高速化)
Alveo U50 latency is <0.5us, CPU latency is 10us. Measured from start of packet in on Tick (Market Data) to Start of Packet out on the order to Start of Packet Out on the Order(estimate)
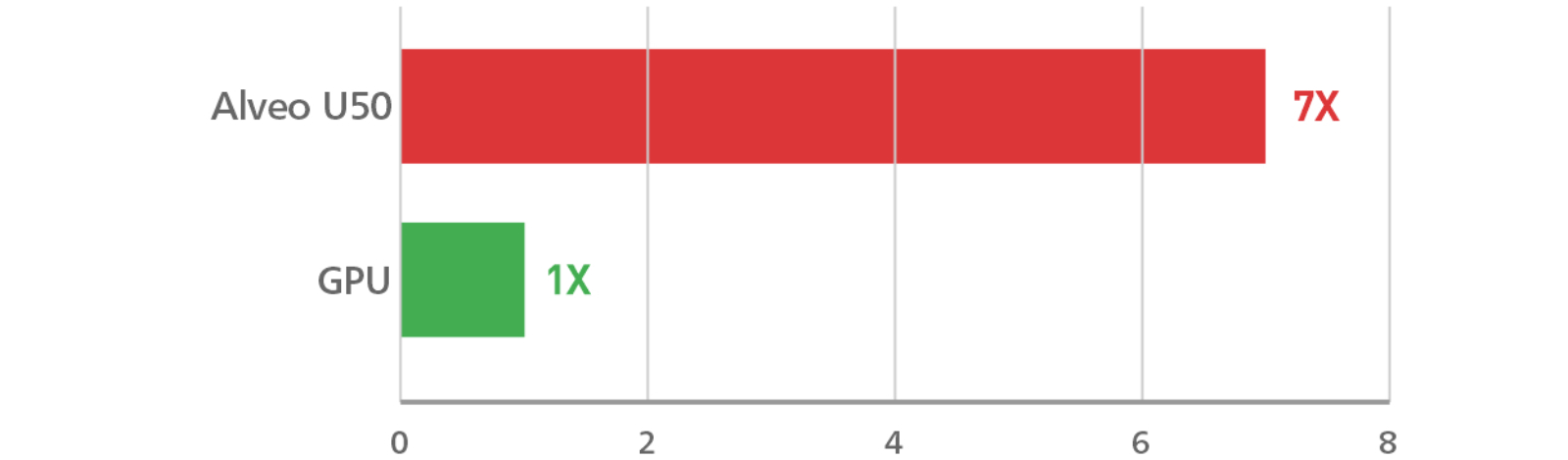
深層学習推論の高速化
- スループット向上(10 倍)- 1 秒間に変換されるシンボル数
- 低レイテンシ(25 分の 1)
- ノードあたりの電力効率が大幅に向上
音声翻訳のスループット
Transformer NMT(シンボル数/秒が高速化)
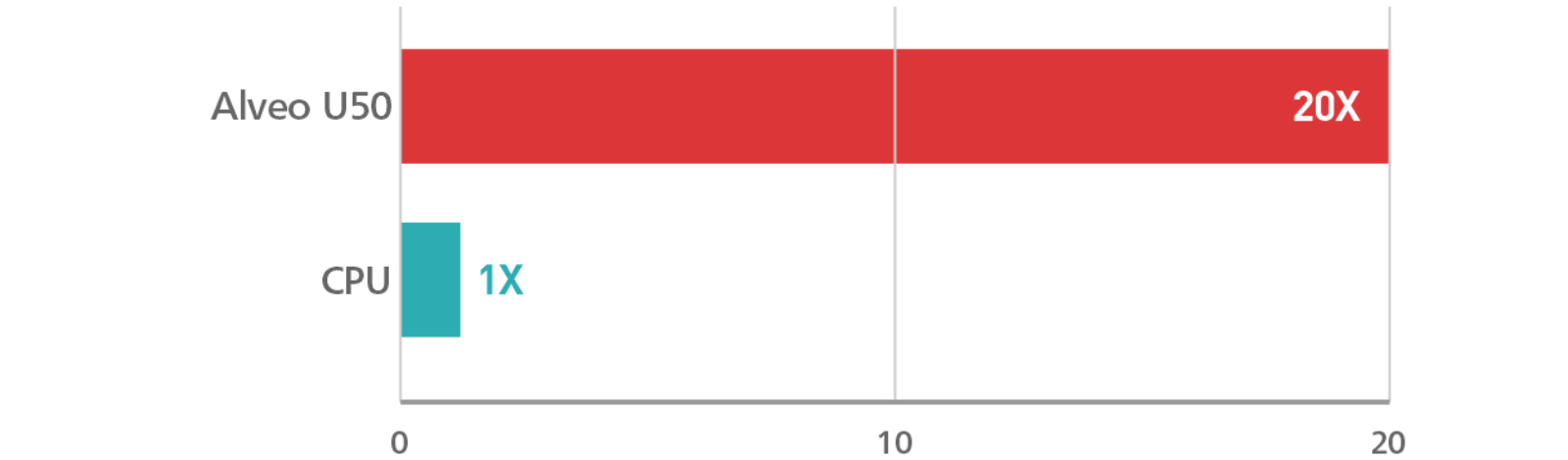
Performance of Alveo U50 – with both Alveo U50 and Tesla T4 running(B=2, L=8), Tesla T4(B=8, L=8)(estimate)
Alveo 1つで幅広い用途に対応
| CPU 逐次処理 |
GPU 並列処理 |
Alveo 逐次処理 + 並列処理 |
|
 |
 |
 |
|
| サードパーティアプリケーション | ● | ● | ● |
| 高レベルコーディング | ● | ● | ● |
| 複雑なメモリとデータパス | ● | ||
| 適応型ハードウェア | ● | ||
| AI 推論 + プリ/ポスト プロセス | ● | ||
| オンボードネットワーク | ● |
HPCテック XILINX ALVEO シリーズ搭載サーバ

VITIS 統合ソフトウェアプラットフォーム、XILINXランタイムライブラリをプリインストール。
導入後すぐにご利用できます。
XILINX ALBEO SERVER HOST MODEL
WORKSTATION
- CPU:1CPU, 2CPU
- Memory:Total Max 1.5TB
- Storage:HDD, SSD, NVMe章
RACKMOUNT SERVER
- CPU:1CPU, 2CPU
- Memory:Total Max 3TB
- Storage:HDD, SSD, NVMe
仕様の相談や見積書のご依頼は担当営業までお問い合わせください。

HPCテック XILINX ALVEO Series ご案内カタログ(2.41MB)
XILINX ALVEO U200&U250・U50・U280 カタログ + 資料リンク

Alveo U200 & U250

Alveo U280

Alveo U50
その他資料リンク
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。